
Implementando o algoritmo K-Means
com linguagem R
O conceito do algoritmo K-Means já foi explicado aqui. Nesta publicação vamos implementar o algoritmo K-Means com linguagem R, mas com objetivo de tentar entender um pouco mais esse método de aprendizado de máquinas não supervisionado.
Para este experimento vou usar um dataset público existente no diretório da UC Irvine. Tive o prazer de conhecer esse repositório quando fiz uma Especialização de Ensino Virtual. Para acessar o repositório e encontrar as dezenas de dataset disponíveis, acesse este link: http://archive.ics.uci.edu/ml/datasets.html. O dataset que vamos usar será Daily and Sports Activities Data Set. Acima de tudo é importante entender que ele apresenta informações de 8 pessoas, entre 20 e 30 anos que realizaram 19 atividades físicas. Sensores de Acelerómetro, Magnetómetro e Giroscópio coletaram dados dos eixos X, Y e Z, ou seja, totalizando 9 registros de dados de cada uma das 5 partes do corpo. Os sensores estavam no Dorso, Braço Direito, Braço Esquerdo, Perna Direita e Perna Esquerda. O arquivo com os dados coletados está no link: http://archive.ics.uci.edu/ml/machine-learning-databases/00256/. Para exemplificar, vamos analisar somente os dados coletados dos sensores das pernas e de um único exercício, mas fique a vontade para fazer com qualquer sensor ou exercício.
Vou entender que você já tem o RStudio em sua máquina, mas caso não tenha, recomendo fortemente que leia isso.
Acessando e recebendo os dados externos
Usando R é possível trabalhar com a leitura e tratamento de dados externos em diversas origens. Pode ser um JSON, um XML, ZIP, e mais uma porção de outros formatos de dados. Neste caso vamos baixar um arquivo Zip e extrair seu conteúdo, em seguida vamos ler os dados e trabalhar com um pouco de descoberta em cima disso com os clusters.
Para baixar o arquivo via código e poder replicar o experimento sempre que precisar, para isso, vamos informar qual será o diretório de trabalho e quais os dados do arquivo que deve ser baixado. Depois de baixar o aquivo de 160MB, é necessário extrair os dados e ver o que aparece.
Em primeiro lugar, veja o código abaixo para saber como fazer isso:
setwd("C:/Temp/KMeans")
url <- "http://archive.ics.uci.edu/ml/machine-learning-databases/00256/data.zip"
destfile <- "data.zip"
download.file(url, destfile, mode="wb")
unzip("data.zip")
O resultado é um conjunto de pastas com diversos arquivos dentro. Entretanto, se navegar pra dentro das pastas, vai encontrar 60 arquivos txt em cada uma das pastas p* (que é uma pra cada das 8 pessoas) e por sua vez estão dentro das pastas a* (que representam as atividades).
Se abrir um dos arquivos txt, irá encontrar as 45 colunas com as coletas de cada um dos sensores. Não se assuste com esse monte de números, tudo ficará mais claro no decorrer do texto.
Transformando os dados do arquivo em um DataFrame do R
Quando se abre o arquivo txt bruto não é tão simples de identificar o que são esses números. Contudo, lendo a documentação do Dataset fornecido no link lá em cima, entendemos a estrutura de como os dados são armazenados e quais são as colunas. Para este experimento, vamos usar a atividade número 15 – Pedalar na bicicleta ergométrica na horizontal – e analisar somente os sensores de pernas. Veja o código abaixo:
atividade <- 15
DadosDeOrigem <- gsub(" ","",paste(getwd(), "/data/a", atividade))
setwd(DadosDeOrigem)
Diretorios <- list.files()
TotalPessoas <- length(Diretorios)
DadoBruto <- NULL
i <- 1
while (i <= TotalPessoas) {
setwd( gsub(" ","",paste(DadosDeOrigem, "/", Diretorios[i])) )
LerArquivos <- list.files()
j <- 1
while (j <= length(LerArquivos)) {
DadoBruto <- rbind(DadoBruto, read.table(LerArquivos[j], sep=","))
j <- j+1
}
i <- i+1
}
#Colocar as colunas que são interessantes analisar
SoPernas <- DadoBruto[,28:45]
colnames(SoPernas) <- c("DAX", "DAY", "DAZ", "DGX", "DGY", "DGZ", "DMX", "DMY", "DMZ", "EAX", "EAY", "EAZ", "EGX", "EGY", "EGZ", "EMX", "EMY", "EMZ")
Para terminar esta parte de acesso, todos os dados de pernas (coluna 28 até 45) da atividade 15 foram armazenados em um novo Dataframe chamado SoPernas. Foi dado um nome para coluna, seguindo a lógica:
- D = Direita
- E = Esquerda
- A = Acelerómetro
- G = Giroscópio
- M = Magnetómetro
A coluna DAX significa D (direita) A (acelerómetro) X (eixo X). A coluna EGZ significa E (esquerda) G (Giroscópio) Z (eixo Z). E assim por diante.
Implementar o algoritmo K-Means com linguagem R
Depois dos dados tratados, usar o algoritmo de K-Means é certamente simples. Ele recebe o dataset que deve ser consultado e o conjunto de segmentos que deve criar. Como já sabemos que são 8 pessoas que fazem parte da amostragem, não precisamos rodar aquele algoritmo de Elbow Method para descobrir quando grupos é possível criar. Veja, por exemplo, o código simples abaixo que recebe o processamento do K-Means e depois mostra a quantidade de elementos do dataframe que foi classificado em cada um dos clusters.
Resultado <- kmeans(SoPernas[1:2], 8) Resultado$size
Após a execução do K-Means, por exemplo, pode-se plotar os dados em um gráfico e ver como o algoritmo separou os dados nos 8 grupos que foram solicitados. Para facilitar o entendimento, vou plotar somente os dados de DAX e DAY, para um gráfico simples de duas dimensões, usando o recurso de poder plotar cada grupo em uma cor diferente para facilitar a análise de quem está observando.
plot(SoPernas[1:2], col = Resultado$cluster, pch= 19)
Se quiser colocar cada ponto central de um centroide, pode usar este exemplo de código abaixo na sequência da plotagem do gráfico:
points(Resultado$centers[,1:2], col="orange", pch=8, cex=2)
Após plotar o gráfico com os 8 segmentos, é possível identificar facilmente os grupos que o K-Means separou.
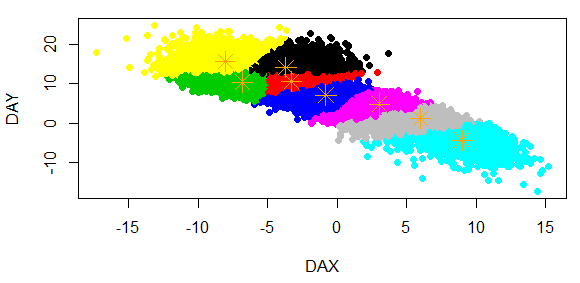
Quando um novo item for inserido no dataset, ele ficará associado a algum dos clusters. Por exemplo, você não precisa necessariamente saber se o dado é de uma mulher de 20 anos ou de um homem de 30, simplesmente ao analisar o dado novo contra os dados já processados, o computador vai entender onde estes dados se enquadram e vai te retornar qual é o gênero e a idade que ele estima que seja. Simples, não?!






