Sistemas de recomendação
para por em prática as regras de associação
Arrisco dizer que o algoritmo Apriori para sistemas de recomendação é a forma mais efetiva para colocar em prática as regras de associação. Mas isso só ocorre porque, para criar regras de forma efetiva, é necessário evitar o trabalho de força bruta.
O princípio do algoritmo Apriori diz que um 𝑘−𝑖𝑡𝑒𝑚𝑠𝑒𝑡 só será entendido como frequente se todos seus (𝑘−1)−𝑖𝑡𝑒𝑚𝑠𝑒𝑡 forem frequentes. Ou seja, um conjunto de itens é frequente se seu suporte, que é a segmentação de registros criando um subconjunto de dados que contém os itens, está acima de um determinado limite mínimo (pode ser chamado de suporte mínimo). Ao se decompor este comportamento em duas fases distintas, pode-se encontrar o subconjunto de itens frequentes quando estes itens satisfazem o mínimo de suporte. E para gerar as regras de associação, a partir destes itens frequentes, deve satisfazer o mínimo da confiança (pode ser chamada de confiança mínima).
Um padrão encontrado nas transações pode ser considerado confiável se ele aparecer em uma alta porcentagem de casos aplicáveis. Contudo, para se trabalhar com regras de associação, também é entendido que o algoritmo é confiável se tiver um valor de confiança alto. A tarefa de encontrar os itens frequentes dentro do conjunto de dados é repetitiva, e se encerra quando a combinação de itens frequentes não for mais satisfatória.
Aplicação do Algoritmo Apriori
Na primeira iteração do processo, o algoritmo gera o 1−𝑖𝑡𝑒𝑚𝑠𝑒𝑡, onde a combinação destes elementos é superior ao suporte que foi definido. Os elementos que satisfazem o valor mínimo de suporte são então selecionados e combinados, gerando o 2−𝑖𝑡𝑒𝑚𝑠𝑒𝑡, e mais uma vez o suporte para esse novo conjunto é calculado. Novamente há uma iteração do processo selecionando itens que satisfaçam o mínimo de suporte e combinada com o conjunto de itens anterior, criando o 3−𝑖𝑡𝑒𝑚𝑠𝑒𝑡. E assim segue com as iterações até que o sub-conjunto de itens criado não satisfaça o valor mínimo de suporte, deixando de ser considerado um conjunto de item frequente.
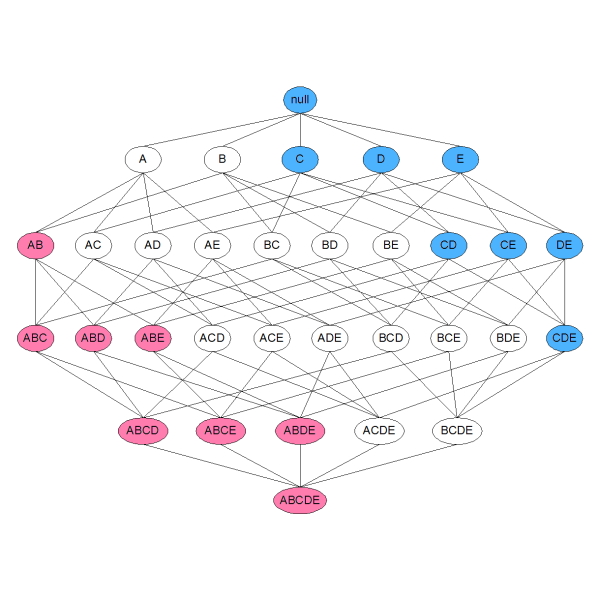
Por exemplo, imagine que esta ilustração em forma de grafo é uma base de dados que será utilizada para criar as regras de associação.

Lembre-se que, se um item é considerado frequente, então todos seus subitens também são considerados frequentes. Para entender essa afirmação, observe a ilustração abaixo (com as marcações em azul) no qual o item 𝐶𝐷𝐸 foi considerado frequente, e consequentemente todos os itens anteriores àquele elemento também são considerados frequentes. A cor azul destaca os nós que foram considerados frequentes dada essa afirmação 𝐶𝐷, 𝐶𝐸, 𝐷𝐸, 𝐶, 𝐷 e 𝐸, incluindo o conjunto vazio, NULL.

Seguindo a mesma estratégia, porém com a lógica invertida, a imagem abaixo (com as marcações em rosa) apresenta o conjunto 𝐴𝐵 que não foi considerado frequente, logo os itens derivados deste item 𝐴𝐵 também serão desconsiderados e não terão regras sendo criadas para os itens 𝐴𝐵𝐶, 𝐴𝐵𝐷, 𝐴𝐵𝐸, 𝐴𝐵𝐶𝐷, 𝐴𝐵𝐶𝐸, 𝐴𝐵𝐷𝐸 e 𝐴𝐵𝐶𝐷𝐸. Com destaque em rosa estão os nós dos itens que foram desconsiderados para a criação das regras.

Métodos de avaliação do algoritmo
Como métodos validados que permitem avaliar a criação das regras de associação, pode-se destacar:
- Medidas objetivas com base em probabilidade de suporte e confiança;
- Medidas subjetivas que definem peculiaridade e surpresa dos dados.
As métricas de Suporte e Confiança já foram discutidas em outro texto.
Peculiaridade: A medida pode ser considerada peculiar se estiver distante de outros padrões descobertos, se baseando em alguma medida de distância. Padrões peculiares são gerados com dados peculiares, que na estatística são conhecidos como outliers. Espera-se que tenha baixa representatividade absoluta na base de dados, e por causa disso, seja significativamente diferente do restante dos dados. Padrões peculiares geralmente são desconhecidos para os usuários, isso traz à tona uma característica interessante que pode passar despercebida pela área de negócio que solicitou o projeto.
Surpresa: Para um padrão ser surpreendente, é esperado que ele contradiga o senso comum, ou expectativas, de um usuário ao analisar o resultado. Um padrão que é uma exceção à regra, ou seja, foge de um padrão geral que já foi descoberto, também podem ser considerados surpreendente. Em grande parte dos casos são descobertas interessantes, porque destacam divergência de conhecimento prévio e pode sugerir uma abordagem de que haja dados que precisam de mais estudos.
Muitas vezes, resultados que apresentam peculiaridade e surpresa, incomodam os “donos de verdades absolutas“. Isso porque estas pessoas não esperavam que o comportamento coletivo fosse diferente do que se era desejado/esperado, baseado em suas crenças.
Material de referência
Como este texto é continuação do que escrevi sobre Explicando o algoritmo de Regra de Associação, as referências são as mesmas. Usei o livro Introdução ao Data Mining. Mineração de Dados e também Introdução à mineração de dados: com Aplicações em R
e o artigo Interestingness measures for data mining: A survey.