Se você quer desenvolver projetos de Machine Learning, então você precisa conhecer o CRISP-DM e o Machine Learning Canvas. Ambas são metodologias bem fundadas para projetos de ML. Assim, a metodologia CRISP-DM, ou Cross-Industry Standard Process for Data Mining, é uma metodologia confiável, desenvolvida há mais de 20 anos, para criar projetos no mundo de Machine Learning. Enquanto o Machine Learning Canvas é uns 15 anos mais novo, consegue apresentar algumas estruturas mais detalhadas para criar modelos.
O Machine Learning é um subcampo da inteligência artificial que, primordialmente, usa algoritmos e modelos estatísticos para realizar tarefas sem programação explícita. Em contrapartida, eles dependem de padrões e inferências. A importância do ML não pode ser subestimada, ele tem o potencial de transformar quase todos os aspectos de nossas vidas, desde a saúde até as finanças, passando pela educação e muito mais. Além disso, está desempenhando um papel cada vez mais importante em entrega de valor nas empresas, e ajuda a identificar padrões, fazer previsões e otimizar processos, tornando os projetos mais eficientes e eficazes.
Este artigo é o primeiro que entra em detalhes na série de Roadmap MLOps 2014, e com toda a certeza, irá lhe guiar através de cada um dos seis elementos do CRISP-DM e do Machine Learning Canvas.
CRISP-DM
O CRISP-DM orienta as equipes através de cada etapa do processo, desde a compreensão do problema de negócio até a implantação do modelo, garantindo que todas as considerações importantes sejam abordadas. Isso resulta em modelos mais precisos, implementações mais suaves e, finalmente, em decisões de negócios mais informadas e eficazes.

- Entendimento do Negócio: Primeiramente, é necessário entender o negócio. Aqui, definimos os objetivos, avaliamos a situação e criamos um plano de mineração de dados. É essencial ter uma compreensão clara do problema que estamos tentando resolver.
- Entendimento dos Dados: Em seguida, precisamos entender os dados. Isso envolve coletar os dados, descrevê-los, explorá-los e verificar sua qualidade. Uma boa compreensão dos dados nos ajudará a construir modelos mais eficazes.
- Preparação dos Dados: A preparação dos dados é onde passamos a maior parte do tempo. Inclui todas as atividades necessárias para construir o conjunto de dados final, desde a limpeza dos dados até a formatação correta para modelagem.
- Modelagem: Na fase de modelagem, aplicamos várias técnicas de modelagem e calibramos seus parâmetros para a melhor solução. O objetivo é selecionar o modelo que melhor atende aos objetivos do negócio.
- Avaliação: A avaliação é o estágio em que avaliamos, de maneira completa e criteriosa, o modelo construído. São verificados se os objetivos do negócio, que foram definidos na primeira fase, foram alcançados.
- Implantação: Finalmente, chegamos à fase de implantação. Aqui, colocamos o modelo em prática, monitoramos seu desempenho e fazemos os ajustes necessários.
Machine Learning Canvas
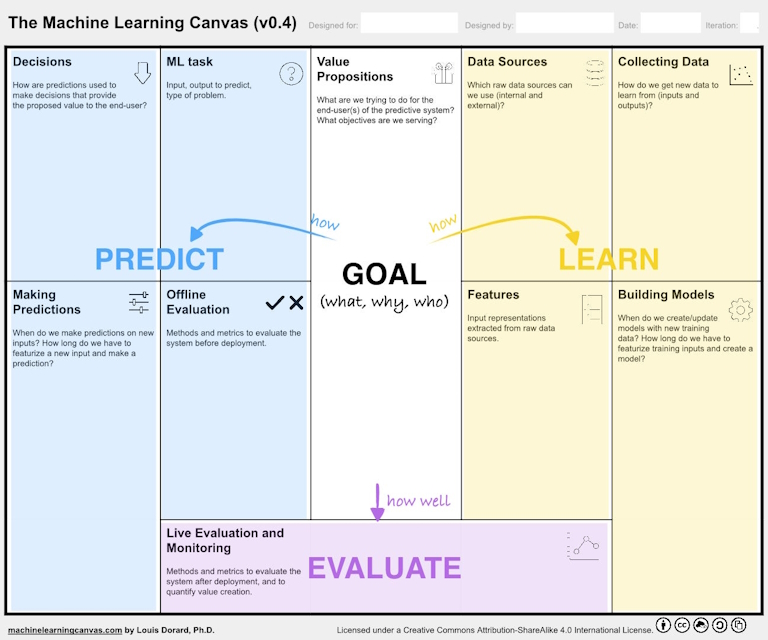
Para facilitar esse trabalho, o pesquisador Louis Dorard criou um framework baseado no Business Model Canvas, porém voltado a Aprendizagem de Máquinas. O trabalho foi publicado em seu site e é constituído de um eBook que pode ser baixado gratuitamente, também fornece acesso a um modelo editável do canvas em PPT. Veja abaixo os detalhes para preencher o Canvas e conseguir desenvolver seus modelos de Machine Learning de forma mais assertiva e com menos “achismos”.
Se você não conseguir baixar o canvas, nem o PPT, me mande uma mensagem e eu lhe encaminho…

Para preenchimento, é importante entender o que há em cada parte do template. Vou usar um dos exemplos que existe no e-book, que fala sobre o desenvolvimento de uma priorização para cliente de e-mail.
- Proposta de valor (value propositions): Primeiramente, define o que se fazer, por que é importante e quem vai usar e ter impacta. Exemplo: tornar mais fácil para os usuários de um cliente de e-mail identificar novas mensagens importantes em sua caixa de entrada.
- Fontes de dados (data sources): Identifica as fontes de dados brutas que irá utilizar para resolver o problema. Exemplo: Mensagens de e-mail anteriores, Livro de endereços e Calendário.
- Coleta de dados (collecting data): Descreve como podemos obter novos dados para aprender (entradas e saídas). Exemplo: os usuários podem rotular manualmente os e-mails como importantes ou não.
- Seleção de características (features): Define quais itens das variáveis existentes nos dados brutos irá utilizar para criar o modelo. Exemplo: Recursos de conteúdo (assunto, corpo, anexos, tamanho), Funcionalidades sociais (informações sobre o remetente, interações anteriores), Rótulos de e-mail.
- Construção de modelos (building models): Em seguida, define como serão feitas as extrações dos dados da base de origem, e quais dados serão utilizados para a construção ou atualização do modelo. Exemplo: criar um modelo por usuário, inicialmente construído com os últimos 12 meses de dados dos e-mails.
- Tarefa de Machine Learning (ML tasks): Define a família de algoritmos que irá utilizar para resolver o problema, as entradas e o resultado esperado. Exemplo: resolver problemas de Classificação Binária.
- Decisões (decisions): Deixa claro como o usuário final irá aproveitar retorno das previsões do modelo. Exemplo: mover e-mails recebidos com uma pontuação de importância acima de um determinado limite, para uma seção dedicada na parte superior da caixa de entrada.
- Fazer previsões (making predictions): Discute o momento no qual o modelo será acionado para responder às chamadas. Exemplo: toda vez que receber um e-mail endereçado ao usuário, que há o inicio de uma nova thread.
- Avaliação offline (offline evaluation): Finalmente, descreve quais métodos e métricas serão utilizados para avaliar a maneira de como as previsões são feitas e utilizadas, antes de ser implantado. Exemplo: usar os últimos 3 meses de e-mails para teste e 12 meses antes para Treinamento.
- Avaliação e monitoramento ao vivo (live evaluation and monitoring): Mede o funcionamento do modelo e monitora se o valor de acertos continua aceitável. Exemplo: avaliar semanalmente os pontos, como o Ratio, que seria a quantidade de erros explicitamente sinalizado pelo usuário dividido pela quantidade de e-mails recebidos.
CRISP-DM e Machine Learning Canvas para projetos de ML
Machine Learning está aqui para ficar, se bem que falo disso há bastante tempo. Contudo, a medida que continuamos a explorar seu potencial, fica claro que ele desempenhará um papel cada vez mais importante em nossas vidas e em nossos projetos. O futuro é brilhante para o Machine Learning, e seja como for, se você estiver preparado para desenvolver projetos envolvendo essa disciplina irá lhe trazer bons frutos. Existem duas metodologias interessantes para se seguir. O CRISP-DM é uma metodologia robusta e flexível que pode se adaptar para qualquer projeto de Machine Learning. O Machine Learning Canvas também é uma metodologia, que explica com um pouco mais de passos as necessidades existentes em projetos. Seguir os passos destas metodologias irá direcionar para que seu projeto esteja no caminho certo para o sucesso. Independente do que escolher para utilizar, não deixe de considerar o CRISP-DM e Machine Learning Canvas para projetos de ML.
Bons projetos!