Medir a performance
da descoberta de padrões
Os processos de descoberta de padrões descritivos e preditivos são diferentes, mas podemos calcular a performance dos algoritmos de Machine Learning com uma Matriz de Confusão. Isso acontece porque da mesma forma que cada tipo de paradigma de Machine Learning varia em seus objetivos de soluções, eles também variam no método de validação.
No caso de um Classificador, que faz parte do paradigma de aprendizagem supervisionada, os dados utilizados para treinar o modelo possuem os dados do atributo previsor e também do alvo. O método mais comum é, utilizando a base de treino e teste, comparar os resultados gerados pelo algoritmo com o que existe na variável alvo. Quanto mais o modelo preditivo responder corretamente na comparação com a classe real que está na variável alvo, mais assertivo está o algoritmo.
Depois de se ter o modelo preditivo ajustado, é possível utilizá-lo para predizer exemplares desconhecidos. Estes exemplares não fazem parte da base de dados utilizada para treinar o modelo. A tarefa de teste apresenta os dados conhecidos para o algoritmo e recebe o resultado da classe predita. Esse resultado é comparado com o que existe na variável alvo e é medido o nível de assertividade do modelo.
Classificação binária
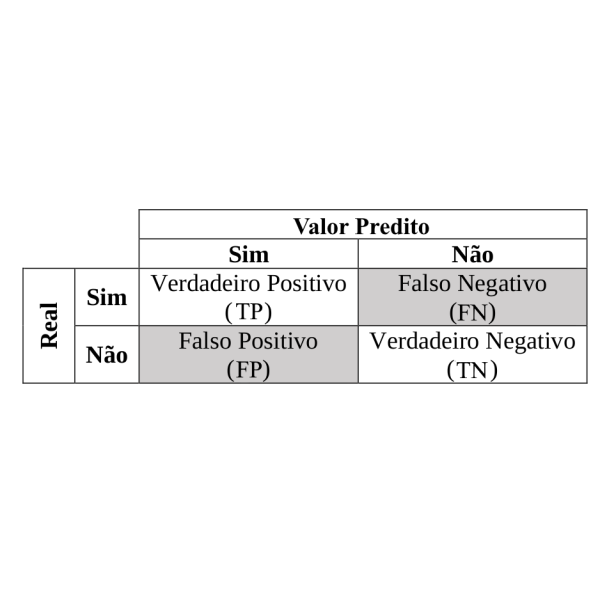
Em problemas de classificação binária é utilizada uma matriz de tabulação cruzada dos resultados preditos com as classes originais observadas, conhecida como matriz de confusão. Contudo, esta matriz busca entender a relação entre acertos e erros que o modelo apresenta. Pode parecer complexo, mas os resultados podem ser resumidos em quatro valores iniciais, sendo:
- Positivo Verdadeiro (True Positive – TP) que significa que a classe prevista e observada originalmente fazem parte da classe positiva;
- Falso Positivo (False Positive – FP) que significa que a classe predita retornou positivo mas a original observada era negativa;
- Negativo Verdadeiro (True Negative – TN) os valores preditos e observados fazem parte da categoria negativa;
- Falso Negativo (False Negative – FN) representa que o valor predito resultou na classe negativa mas o original observado era da classe positivo.
Taxas de erros e acertos
Com base nos resultados da matriz de confusão da classificação binária, outros valores podem ser calculados:
- Taxa Positiva Verdadeira (True Positive Rate – TPR), ou sensibilidade. É a proporção de resultados corretamente classificados como positivo no resultado do modelo. Este resultado é comparado com todos os valores definidos como positivos na amostra, sendo calculado como 𝑇𝑃𝑅=𝑇𝑃(𝑇𝑃+𝐹𝑁).
- Taxa Negativa Verdadeira (True Negative Rate – TNR), ou especificidade. É a proporção de resultados classificados como negativos fora de todas as instâncias que não eram originalmente negativos. Pode ser calculado com 𝑇𝑁𝑅=𝑇𝑁(𝑇𝑁+𝐹𝑃).
- Taxa de Falsos Positivos (False Positive Rate – FPR). É calculada por 𝐹𝑃𝑅=1−𝑇𝑁𝑅.
- Taxa de Falsos Negativos (False Negative Rate – FNR) tem a formalização na equação 𝐹𝑁𝑅=1−𝑇𝑃𝑅.
Um classificador que tenha bom desempenho dará um alto TPR e TNR, mas baixos FPR e FNR.
Métricas de avaliação da Matriz de Confusão
- Acurácia (Acurary): Quantidade classificada como Positivos e Negativos corretamente, e pode ser formalizada em (TP + TN) / (TP + TN + FP + TN)
- Precisão (Precision): Quantidade Positiva classificada corretamente. E é calculada por TP / (TP + FP)
- Recall: Taxa de valores classificada como Positivo, comparada com quantos deveriam ser. E pode ser calculada como TP / (TP + FN)
- F1 SCORE: É calculado como a média harmônica entre Precisão e Recall, sendo sua formulação matemática representada por (2* TP) / (2* TP + FP + FN)
Para classificadores que fornecem saídas probabilísticas, a sensibilidade (TPR) pode ser aumentada diminuindo o limiar de P, mas isso aumenta automaticamente o FPR. A curva de característica de operação do receptor (Receiver Operating Characteristic – ROC) e a área sob a curva ROC (Area Under the ROC curve – AUC), por exemplo, são usados para comparar o desempenho de algoritmos. Contudo esse desempenho é representado na faixa de limites normalizados entre 0 e 1. A curva ROC ideal tende ao canto superior esquerdo, resultando em alta TPR e baixa FPR. E por isso o máximo valor possível para AUC é 1.
Esta é uma forma rápida e simples de entender como é a performance de algoritmos de Machine Learning, especificamente da Matriz de Confusão usada em um classificador binário.
Alguns livros que me ajudaram a entender esse comportamento foram Introdução à Mineração de Dados: Com Aplicações em R e Data mining
.