
Fala galera, como prometido neste post e iniciado pela Árvore de Decisão, hoje continuo a série de posts falando sobre os algoritmos de Data Mining existentes no SQL Server 2014.
Este segundo algoritmo que vamos falar é de Regras Associativas. Voltando ao primeiro post, as Regras Associativas apresentam uma estrutura combinatória dentro de um DataSet a partir de itens similares que estão sendo processados. A maioria dos sistemas inteligentes que utilizam este algoritmo são criados para recomendar um produto para o usuário, normalmente em e-commerce. Já reparou que quando acessa o site da Amazon e procura o livro Do Banco de Dados Relacional à Tomada de Decisão, e vários outros livros de Business Intelligence e BigData são apresentados? Então, não existe um Oompa-Loompa colocando isso aleatoriamente para você. Por trás, existe um sistema de recomendação completo, provavelmente utilizando a categoria “Computação, Informática e Mídias Digitais” como um parametro de entrada para este item. Como sempre, é importante conhecer a base e saber quais segmentações você quer aplicar para a recomendação. Neste caso, quando se coloca a categoria como um parametro de entrada, sempre serão recomendados itens similares dentro desta categoria, mas se todos os compradores do meu livro também comprassem um livro de culinária, ele não apareceria na recomendação pois está em outra categoria.
Bom, já entendemos a aplicabilidade e como ele funciona, agora vamos criar um exemplo para o Adventure Works?
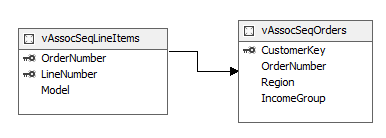
Primeira coisa é necessário criar um novo projeto do tipo SSAS com Data Mining. Mais uma vez vou acreditar que você sabe criar um Data Source apontando para o AdventureWorksDW2012 e um Data Source View apontando para a vAssocSeqLineItems e vAssocSeqOrders. Esta estrutura basicamente é um relacionamento entre pedidos e produtos. Onde uma view tem os pedidos que foram feitos, e na outra view tem a lista de produtos que estão associadas àquele pedido. Consegue ver um relacionamento entre essas views? E a aplicabilidade desse relacionamento na nossa recomendação de conteúdo? Caso não tenha conseguido descobrir essa associação, a idéia é encontrar na lista de itens os produtos que também são comprados (com base na outra view de pedido) quando ao menos um daqueles itens é o que está no meu carrinho. Ficou mais claro? Não? Ok, vamos continuar e ver se conseguimos explicar… Voltando pra Amazon, e olhando a categoria do meu livro. Diversas pessoas olham meu livro e alguns outros livros na mesma visita à pagina, não importa a ordem, pode ser que vejam outros livros e depois o meu (a ordem de visualização vai importar quando estivermos falando de algoritmo de Sequence Cluster, mas isso é pra outro post). O importante é que existe uma ligação entre a visita e os produtos que foram vistos, no caso estes livros. Depois de algum tempo, estes livros passam a ter um relacionamento mais preciso, pois tem mais gente visualizando os livros. Não significa que em todos os acessos os visitantes visualizam todos os livros, estes que estão recomendados são os 5 livros que mais se relacionam com o meu no momento do processamento e dentro naquela categoria que está sendo processada. Pode ser que no futuro um outro livro passe a ser visualizado sempre que alguém buscar o meu livro, isso fará com que o 5º livro da ordem, que seria representado por uma ligação mais fraca, pare de aparecer na recomendação e entre esse outro livro… Tudo isso automaticamente, sem a intervenção daquele Oompa-Loompa comentado lá em cima.
Voltando ao exemplo, depois de incluir o Data Source View, é preciso relacionar as views, arrastando o campo OrderNumber da view vAssocSeqLineItems para cima do campo vAssocSeqOrders.
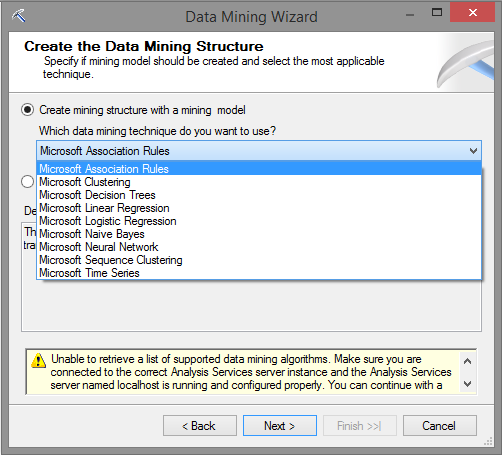
Próximo passo é hora de criar o Mining Model para as regras associativas, faça isso clicando com o botão dirento em Mining Structure e criando um novo a partir do From existing relational database or data warehouse e escolhendo Microsoft Association Rules.
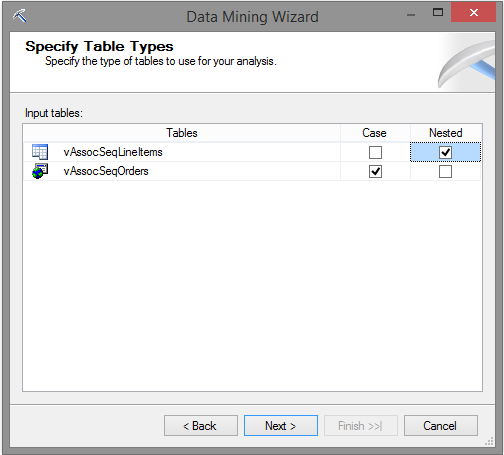
Ao avançar para as próximas telas, deve-se informar qual view é Case e qual é Nested. Neste caso, a estrutura de CASE é onde temos a informação principal que será usada para segmentar os dados. Fazendo uma analogia ao livro, é onde se encontra a categoria de “Computação, Informática e Mídias Digitais” e não os livros que foram visualizados juntos. Já a tabela NESTED é onde se encontram estes livros que foram visualizados juntos. Então selecione vAssocSeqOrders para Case e vAssocSeqLineItens para Nested.
Ao avançar para a tela seguinte, é solicitado para informar quais campos serão tratados como Key, Input e Predictable. A seleção destas colunas é baseada na mesma explicação que foi feita no post sobre Árvores de Decisão, então dê um pulinho lá e veja o que é. Desmarque todas as opções que vierem marcadas, e selecione as caixas de OrderNumber como chave (coluna key) e as três colunas da Model. Sua seleção ficará assim:
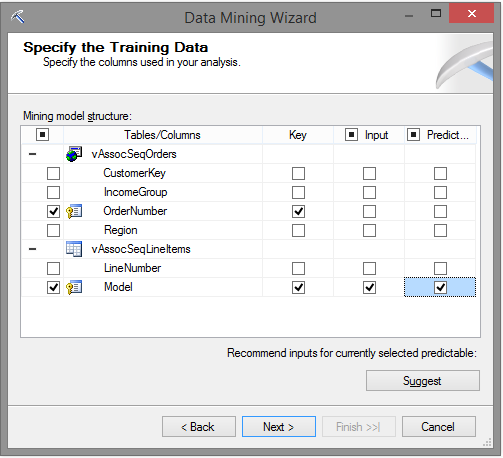
Quando avançar para a próxima tela, garanta que ambas colunas selecionadas estejam marcadas como Key, no Content Type.
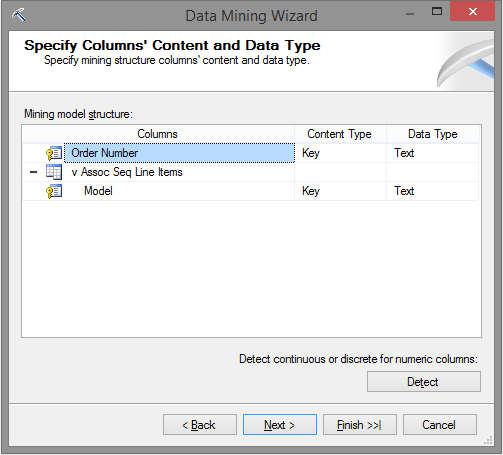
Só pra lembrar, como neste caso é importante a acertividade na recomendação dos itens similares, altere de 30 para 0 o valor do campo “Percentage of Data for Testing“. Avance até finalizar o processo.
Se tudo ocorreu direito, seu Mining Structure ficará assim:
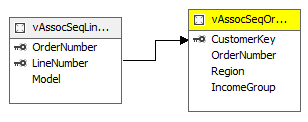
Antes de processar seu projeto, lembre-se de informar qual é o servidor que tem o SQL Server Analysis Services instalado e configurado. Após este pequeno detalhe, faça o processamento.
Após processar, mude a aba do seu Mining para Mining Model View, e então, dentro desta aba, vá até o item Dependency Network.
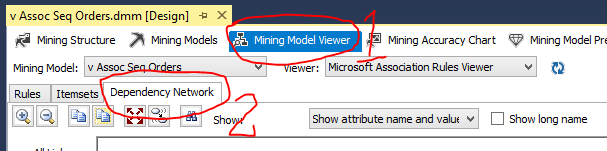
Aqui dentro é possível ver os nós de associação que foram criados.
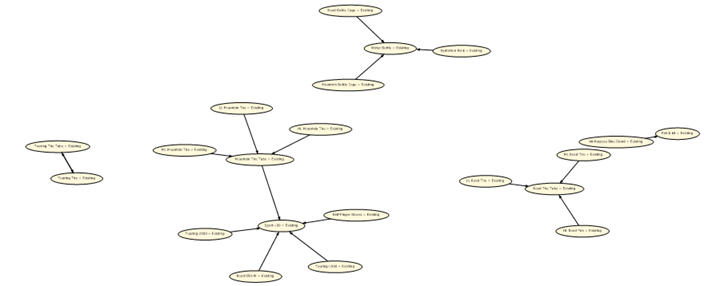
Parece pouca associação (mas por trás não é), isso acontece pela parametrização da quantidade mínima de ocorrências similares dos objetos. Para aumentar isso, volte até a aba Mining Model, clique com o botão direito em Set Algorithm Parameters.
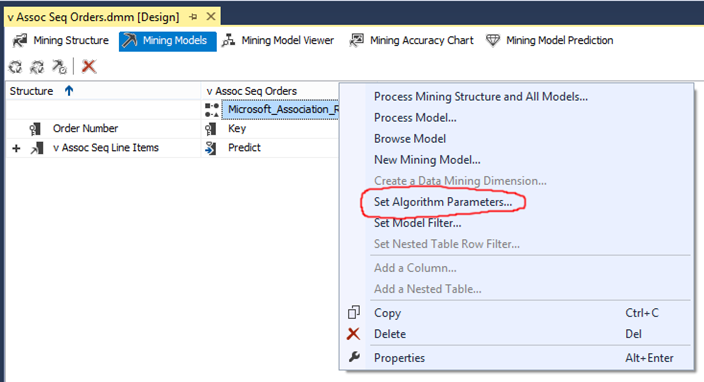
Altere os parametros de Minimum_Support para 0.01 e de Minimum_Probability para 0.1, ao terminar esta alteração, processe novamente seu modelo e em seguida volte a visualizar as associacões (aba Dependency Network do seu Mining Model View). Veja que agora está bem mais completo e bonito de ver.
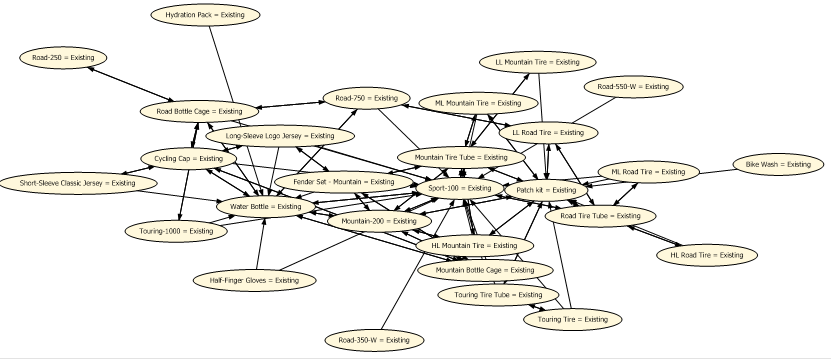
Para consumir as associações, é possível escrever códigos DMX (Data Mining Extentions) passando como parâmetro o nome de um dos produtos, e recebendo uma lista dos outros itens que são associados à ele nas compras. Está no meu pipe pra escrever uma app em .Net que consuma esses dados via DMX, e claro, postar aqui como foi feito J

