
Fala galera, este é o ultimo post sobre a parte estrutural do Partition Table, e é onde se cria a tabela utilizando os conceitos vistos nos posts anteriores.
Para conseguirmos comparar o desempenho de uma tabela com os dados em um unico Filegroup (tbVisitas) e a tabela com todo o Partition Table, criaremos uma segunda tabela (tbVisitas_2) exatamente com a mesma estrutura da tabela anterior e vamos popular com os mesmos dados inseridos anteriormente na tabela inicial.
Veja a criação da tabela, informando o Partition Scheme (veja a linha 5) em frente ao ON, que pode ser colocado ou não na criação da tabela. Caso não informe, o SQL Server cria a tabela com o filegroup padrão, que geralmente é o primary. Quando informamos um Partition Scheme na criação da tabela, os dados passam a utilizar o Partition Scheme para escrever no filegroup correto, que na sequência consulta o Partition Function para saber qual é o algoritmo de quebra dos dados…
1: CREATE TABLE tbVisitas_V2
2: (id INT IDENTITY(1,1)
3: ,nome VARCHAR(50)
4: ,data DATE)
5: ON MuseuPorMesScheme(data)
6: GO
E aqui é a inserção dos dados exatamente igual à tabela original:
1: INSERT INTO TBVISITAS_V2(NOME,DATA)
2: SELECT NOME,DATA FROM TBVISITAS
3: GO
Pra fixar a idéia, lembre-se da imagem postada em Partition Table (Definições/Terminologias) – Parte#3:
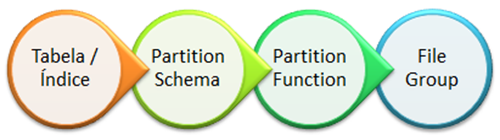
Com isso, conseguimos separar em diversos Filegroups, que por sua vez estão em discos separados, garantindo alta-performance nas consultas realizadas nesta tabela.
Façam testes com essa série de posts em seus projetos e comprovem do desempenho. Convido vocês a postarem nos comentários, o comparativo que fizerem da performance de antes e depois do Partition Table! Quem será o primeiro?
![]()

